
You may need to extract specific pages from PDF documents or may need to split large PDF documents into smaller parts. As a Python developer, you can easily extract specific pages from PDF documents by page numbers or by a range of pages programmatically. In this article, you will learn how to extract specific pages from PDF documents using a REST API in Python.
The following topics shall be covered in this article:
- Document Splitter REST API and Python SDK
- Extract Specific Pages from PDF using a REST API
- Extract Pages by Page Range using Python
Document Splitter REST API and Python SDK
For extracting pages from PDF documents, I will be using the Python SDK of GroupDocs.Merger Cloud API. It is a feature-rich and high-performance Cloud SDK used to merge several documents into a single document. It also enables you to split a single document into multiple documents. The SDK offers functionality to delete, exchange, rotate or change the page orientation for a whole or preferred range of pages and perform other manipulations easily for any supported file formats such as PDF, Word, Powerpoint, and Excel worksheets. Currently, it also provides .NET, Java, PHP, Ruby, Android, and Node.js SDKs as its document merger family members for the Cloud API.
You can install GroupDocs.Merger-Cloud to your Python project using the following command in the console:
pip install groupdocs_merger_cloud
Please get your Client ID and Client Secret from the dashboard before you start following the steps and available code examples. Once you have your ID and secret, add in the code as demonstrated below:
Extract Specific Pages from PDF using REST API in Python
You can extract specific pages from PDF documents by following the simple steps mentioned below:
- Upload the PDF file to the Cloud
- Extract Specific Pages by Page Numbers from the uploaded PDF file
- Download the extracted file(s)
Upload the Document
First of all, upload the multipage PDF document to the Cloud using the code example given below:
As a result, the PDF file will be uploaded to Cloud Storage and will be available in the files section of your dashboard.
Extract Specific Pages by Page Numbers using Python
Please follow the steps mentioned below to extract a specific page or multiple pages from a PDF document programmatically.
- Create a Document API instance
- Provide SplitOptions
- Set the input file path
- Set the Output directory path
- Provide comma-separated page numbers to extract
- Set mode to Pages
- Create SplitRequest
- Get results by calling the DocumentApi.split() method
The following code example shows how to extract pages by providing specific page numbers from a PDF document using a REST API.
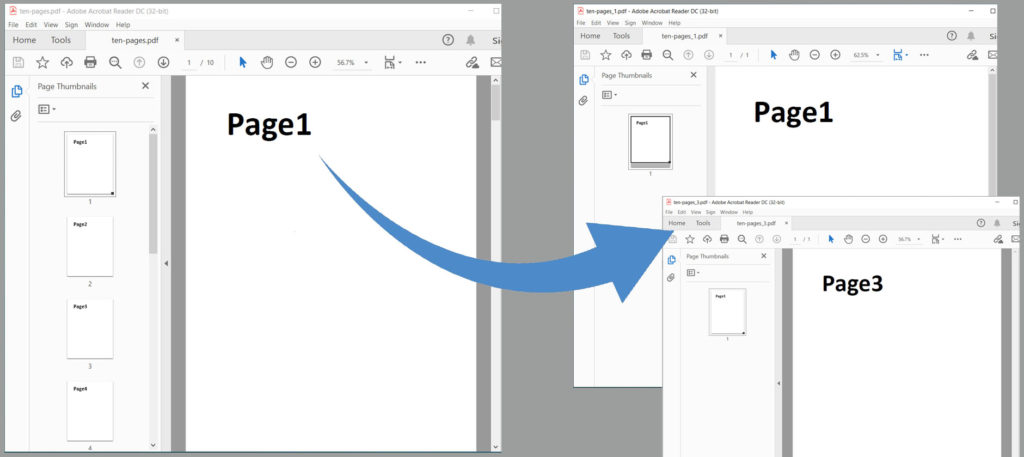
Extract Specific Pages From PDF using Python
Download the Extracted Page Files
The above code sample will save the extracted pages in separate PDF files on the cloud. You can download them using the following code sample:
Extract Pages by Page Range using Python
Please follow the steps mentioned below to extract pages from a PDF document by providing a page range programmatically.
- Create a Document API instance
- Provide SplitOptions
- Set the input file path
- Set the Output directory path
- Provide page range by setting start page number and end page number to extract
- Set mode to Pages
- Create SplitRequest
- Get results by calling the DocumentApi.split() method
- Create DownloadFileRequest
- Download the file by calling the FileApi.download_file() method
The following code example shows how to extract pages by providing a page range from a PDF document using a REST API. Please follow the steps mentioned earlier to upload the files.

Extract Pages by Page Range using Python
Try Online
Please try the following free online PDF splitter tool, which is developed using the above API. https://products.groupdocs.app/splitter/pdf
Conclusion
In this article, you have learned how to extract specific pages from PDF documents on the cloud using Python. You also learned how to programmatically upload the PDF file on the cloud and then download the extracted files from the cloud. You can learn more about GroupDocs.Merger Cloud API using the documentation. We also provide an API Reference section that lets you visualize and interact with our APIs directly through the browser. In case of any ambiguity, please feel free to contact us on the forum.